아키텍처 관점에서 본 차세대 컴퓨팅 -클라우드 컴퓨팅을 위한 플랫폼 기술
클라우드 컴퓨팅의 개념이나 정의는 벤더에 따라 다소 다를 수는 있지만 구글의 플랫폼과 기술이 클라우드 컴퓨팅을 구현하는 핵심 기술이라는 점에는 많은 이들이 공감하고 있다. 2부에서는 이러한 맥락에서 클라우드 컴퓨팅 구현을 위한 플랫폼 기술 가운데 일부를 분산 데이터 저장, 분산 컴퓨팅, 클러스터 관리 세 가지 관점에서 살펴보고자 한다.
2007년 가을, 구글과 IBM이 워싱턴대학교, 버클리공대와 같은 미국 주요 대학을 대상으로 교육과정을 공동 개설했다는 내용이 IT 관련 대중 매체를 통해 발표되었다. 교육기간 동안 학생들은 구글과 IBM 데이터센터에서 제공하는 대규모 병렬 컴퓨팅 인프라에 접속해 다양한 실험을 해볼 수 있었고 새로운 유형의 애플리케이션을 개발할 수 있었다.
기술 구현을 둘러싼 세 가지 시각
이때 IT 관련 매체들은 이 산학 협동 프로젝트를 클라우드 컴퓨팅이라는 이름으로 집중적으로 다루기 시작한 것이 클라우드 컴퓨팅의 시작이라고 할 수 있다. 그럼 먼저 첫 번째 관점인 분산 데이터 저장을 통해 클라우드 컴퓨팅을 살펴보자.
분산 데이터 저장 기술분산 데이터 저장 기술은 네트워크상에서 데이터를 저장, 조회, 관리할 수 있는 기술로서 다양한 영역의 제품과 기술들이 있으며 구글 클라우드 컴퓨팅에 해당하는 플랫폼 기술은 분산 파일시스템과 분산 데이터관리시스템이 있다.
분산 파일시스템은 네트워크상의 여러 서버에 데이터를 블록 단위로 나눠 관리하는 시스템이며 대표적인 공개 소프트웨어로는 CODA, Andrew, Lustre, 아파치 Hadoop, Redhat GFS 등이 있다. 구글의 GFS는 비공개 버전으로 논문으로만 기술 및 아키텍처에 대해 발표한 상태이다. 구글, IBM의 공동 프로젝트에서는 Hadoop 분산 파일시스템을 기반 플랫폼으로 채택해 사용하고 있다. 분산 파일시스템은 일반적으로 메타 정보를 관리하는 마스터서버와 실제 데이터가 저장되어 있는 슬레이브 서버로 구성되며 저가의 하드웨어를 사용해서 고성능과 확장성을 쉽게 이룰 수 있는 장점이 있다.
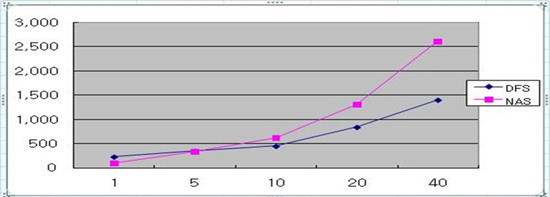
<그림 1>은 10대의 PC급 서버로 구성된 Hadoop 분산 파일시스템과 NAS 1대를 대상으로 한 IO 성능 측정 결과이다. 5MB 파일 쓰기이고 가로축은 동시 사용자 수, 세로축은 응답시간(ms)을 나타낸다.
<그림1> Hadoop DFS IO 성능 측정 결과
결과에서 알 수 있는 것처럼 분산 파일시스템은 동시 사용자와 대용량 IO 처리에 효율적인 장점을 지닌다. 물론 이러한 분산 파일시스템은 일반적으로 기능적인 제약(예: Random Write 미 지원 등)이 있어서 범용적인 활용보다는 대용량 파일이나 멀티미디어 등의 특수한 용도로 사용되는 경우가 많다(아키텍처 및 동작 원리는 잠시 후 다루기로 한다).
<그림2> Message Passing Interface
분산 데이터 관리 시스템은 대용량의 정형화된 데이터를 네트워크로 연결된 다수의 서버에 분산 저장하고 관리할 수 있는 시스템이며 사용자에게는 SQL과 비슷한 간단한 질의 인터페이스를 제공한다. 전통적인 RDBMS(관계형 데이터베이스 관리시스템)에서 기능적인 측면을 다소 희생하고 대신 확장성과 대용량 처리 성능을 높인 시스템이라고 볼 수 있다.
공개 소프트웨어로는 아파치 HBase, HyperTable 등이 있으며 아직은 베타 버전 상태라 기능이나 안정성 측면에서 개선해야 할 부분이 많아 보이지만 지속적으로 발전되고 있는 상황이다. 구글의 BigTable, Amazon Dynamo는 비공개 버전으로 역시 논문을 통해서만 발표되었으며 각 업체 내부에서 다양한 업무에 사용되고 있다.
분산 컴퓨팅 기술
분산 컴퓨팅 기술은 네트워크에 연결된 컴퓨터들의 처리능력을 이용해 거대한 계산문제를 빠르게 처리해 주는 기술이며 P2P, 병렬처리, 그리드(Grid) 컴퓨팅과 유사한 의미를 갖는다. 이중 구글과 IBM이 사용한 방식인 네트워크 기반 병렬 컴퓨팅 기술을 중심으로 살펴보자. 병렬 컴퓨팅 모델을 몇 가지로 나누어 보면 다음과 같다.
- 메시지 전달 방식: MPI(Message Passing Interface), PVM(Parallel Virtual Machine) 등
- 분산 공유 메모리 모델: OpenMP(Open Multi-Processing), Linda, TupleSpace, JavaSpace 등
- 데이터 병렬 모델: MapReduce 등
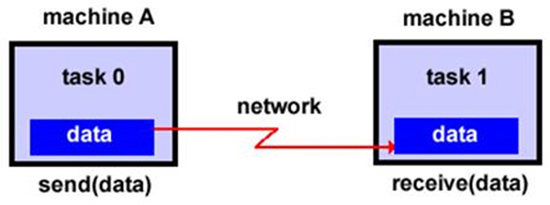
메시지 전달 모델은 여러 개의 태스크(Task)가 몇 대의 서버에 나누어져 실행되었을 때 서버간에 메시지를 전달하면서 병렬로 컴퓨팅을 수행하는 방식이다. 메시지는 데이터, 송신지, 수신지 주소로 구성되며 MPI가 사실상의 업계 표준이다.
분산 공유 메모리 모델은 네트워크로 연결된 다수 서버의 물리적인 메모리를 논리적인 공유 메모리로 구성해 사용자에게는 마치 1대의 서버를 대상으로 작업하는 것처럼 보여주게 하는 기술이다. 사용자 관점에서 쉽게 병렬 컴퓨팅을 할 수 있다는 것이 공유 메모리 모델의 장점이라고 할 수 있다.
각각의 모델은 업무의 성격 및 규모를 감안해 혼합해서 사용할 수 있다. MapReduce는 구글과 야후 같은 글로벌 인터넷 업체들이 선택한 컴퓨팅 모델로서 대용량의 데이터를 처리하기에 적합한 방식이다. 메시지 전달이나 공유 메모리 모델이 계산을 위해 데이터를 가져오는 방식이라면 MapReduce는 데이터가 있는 곳으로 찾아가 계산 작업을 수행하는 방식이므로 네트워크 사용 측면에서 효율적이다. MapReduce와 관련된 대표적인 공개 소프트웨어로는 아파치 Hadoop이 있으며 파일시스템과 함께 MapReduce도 구글, IBM 공동 프로젝트에서 기반 플랫폼으로 사용되고 있다.
클러스터 관리 기술
클러스터는 비슷한 목적을 위해 상호작용하는 컴퓨터들의 그룹으로 볼 수 있다. 위키피디아(Wikipedia)의 클러스터 분류 방식을 참조하면 클러스터는 구성 컴퓨터들의 속성 및 관계에 의해 다음과 같은 유형으로 구분할 수 있다.
- 고 가용성(HA) 클러스터: Failover 클러스터라고도 부르며 서비스의 가용성을 높이기 위한 목적으로 구현된다. 여러 대의 서버들 중에 1대가 주(Active) 서버 역할을 하고 나머지는 보조(Standby) 서버로 동작하다가 주 서버가 장애로 다운되면 보조 서버 중 1대가 주 서버로 선출되어 서비스 가용성을 유지하는 형태로 구성된다. 구글에서는 내부적으로 Chubby라는 Failover 클러스터를 구현해 다양한 업무에 활용하고 있다. 공개 소프트웨어로는 Linux-HA 프로젝트가 있다.
- 부하분산(Load-Balancing) 클러스터: 1대 이상의 부하를 분산시키는 프런트 시스템(웹 서버, L4 스위치 등)이 있으며 이 프런트 시스템이 들어오는 작업들을 백엔드(Backend) 시스템들에 분배시켜 주는 방식으로 클러스터가 가동된다.
- 컴퓨팅 클러스터: 고성능 연산을 제공하기 위한 목적으로 구성된 컴퓨터들의 집합으로 볼 수 있으며 그리드 컴퓨팅이라고도 부르기도 한다. 앞의 분산 컴퓨팅 기술에서 설명한 기술들도 일종의 컴퓨팅 클러스터라고 볼 수 있다.
실제 서비스 환경에서는 한 가지 클러스터 유형이 아니라 여러 가지 유형이 혼합되어 사용된다. 그러면 이러한 클러스터를 구성 및 관리하기 위해 필요한 요소 기술을 몇 가지 살펴보자.
- 서비스 프로비저닝(Service Provisioning): 필요한 순간에 동적으로 자원 할당을 수행해 서비스를 생성 및 제공할 수 있는 기술이다. 프로비저닝이 되기 위해서는 실시간으로 자원의 상태를(Resource Management) 관리할 수 있는 메커니즘을 가지고 있어야 한다. 이 기술은 기존의 온 디맨드(On Demand) 컴퓨팅이나 유틸리티(Utility) 컴퓨팅이라고 불리어왔던 솔루션에 주요 요소 기술로 사용되어 왔으며 최근에는 클라우드 컴퓨팅에도 주요 기술로 사용되고 있다.
- 작업 스케줄링(Job Scheduling): 분산된 네트워크 환경에서 자원을 효율적으로 사용할 수 있도록 우선순위를 정해 실행시킨다. 실행 중에 더 높은 우선순위의 작업이 들어오면 상태를 저장하고(Check Pointing) 나중에 재실행되기도 한다. 지금까지는 주로 배치 연산(Batch Processing) 작업에 활용되었으며 최근에는 온라인성 업무에도 조금씩 활용되고 있다.
관련 아키텍처 및 구성 요소
앞 절에서 설명한 각 플랫폼 기술들은 실제 클라우드 컴퓨팅 인프라 내에서 조직적이고 유기적으로 상호작용하면서 동작한다. 간단하게 사용자의 요청 작업을 처리하는 과정을 살펴보자. 사용자 요청이 들어오면 앞 단의 클러스터 관리시스템은 사용자의 요청 내용을 분석한다. 작업이 대규모 컴퓨팅 파워가 필요한 것인지, 필요하다면 몇 대의 컴퓨팅 자원을 실시간으로 배치해 요청 작업을 처리할 것인지, 아니면 단순히 입력되어 있는 데이터를 조회해 반환해 주면 되는 것인지 등을 파악하고 필요한 실행 환경을 동적으로 구성해 요청을 처리한다. 이 과정 속에는 효율적인 부하 분산과 작업에 대한 스케줄링 그리고 장애 발생 시 어떻게 복구해서 재실행할 것인지에 대한 알고리즘과 메커니즘이 플랫폼 기술들 내/외부적으로 구현되어 상호작용하게 된다. 이러한 일련의 복잡한 행위들은 사용자에게 추상화되어 있으며 사용자는 다만 컴퓨팅 인프라에서 제공하는 사용자 인터페이스를 사용해 원하는 서비스를 사용하기만 하면 된다.
지금부터는 클라우드 컴퓨팅의 플랫폼 기술 중 최근 IT 업계에서 다양하게 활용되고 관련 연구도 활발하게 진행되고 있는 일부 공개 소프트웨어 프로젝트를 중심으로 아키텍처 및 동작 원리를 살펴보고자 한다.

<그림3> 클라우드 컴퓨팅 플랫폼 구성도
분산 파일시스템
분산 파일시스템의 아키텍처 및 동작 원리를 이해하고 직접 실험도 해볼 수 있는 Hadoop이라는 프로젝트가 있다. Hadoop은 분산 파일시스템과 병렬 컴퓨팅 프레임워크로 구성되어 있으며 각각은 구글의 파일시스템인 GFS, 병렬처리 프레임워크인 MapReduce와 아키텍처 및 기능적인 관점에서 거의 동일하다. 이미 설명한 것처럼 구글과 IBM의 공동 프로젝트에서는 클라우드 컴퓨팅의 인프라를 구성하는 데 Hadoop 플랫폼과 IBM의 자체 솔루션인 Tivoli를 사용했고, 그 기반 위에서 다양한 교육 및 실험을 진행하고 있다.
Hadoop DFS(분산 파일시스템)는 파일들의 메타정보를 관리하는 Na menode(마스터)와 실제 데이터 블록들을 관리하는 다수의 Datanode(슬레이브) 서버들로 구성된다. Hadoop DFS는 응용 애플리케이션 계층에서 구현된 파일시스템으로 NAS(Network Attached Storage), SAN(Storage Area Network) 등과 같이 상대적으로 고가의 장비를 사용하는 것이 아니라, 일반 PC급 장비와 여기에 장착되는 SATA 디스크를 이용하면서도 고 가용성을 보장하는 파일시스템이다. 하나의 큰 파일을 여러 개의 작은 논리적인 블록(일반적으로 64MB)으로 나눈 다음, 이 블록을 n개의 서버에 나눠 저장한다. 이렇게 함으로써 하나의 파일에 대한 처리를 여러 서버에 나눠 처리할 수 있어 대용량 파일을 분산 처리하는 데 효과적이다. 또한 파일의 각 블록을 복제해(3 Replica) 다른 서버에 저장함으로써 특정 서버(Datanode) 장애가 발생해도 복제 본이 있는 다른 서버(Data node)에서 데이터를 제공하는 방식으로 고가용성을 보장한다.
IO 동작 방식을 살펴보면, Hadoop DFS에 하나의 파일을 쓸 때 클라이언트는 먼저 Namenode에게 질의한다. 그러면 Namenode는 클라이언트에게 Datanode들의 주소를 반환하고, 클라이언트는 각 Datanode들에 차례로 접속해서 해당 파일의 블록을 쓴다. 모든 블록들의 쓰기 작업이 정상적으로 완료하면 클라이언트는 Namenode에게 완료되었다는 메시지를 보내고 Namenode는 마지막으로 메타정보를 업데이트하면서 파일 쓰기 작업을 종료시킨다. 파일 읽기 작업도 같은 방식으로 동작한다.
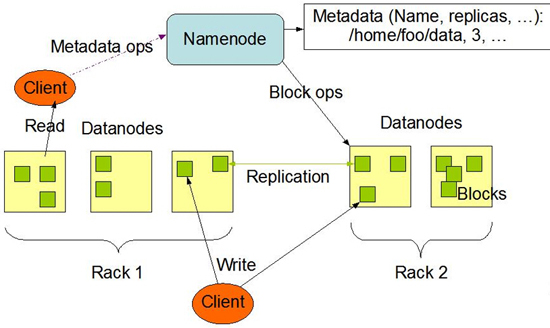
<그림4> 분산 파일시스템 구성도
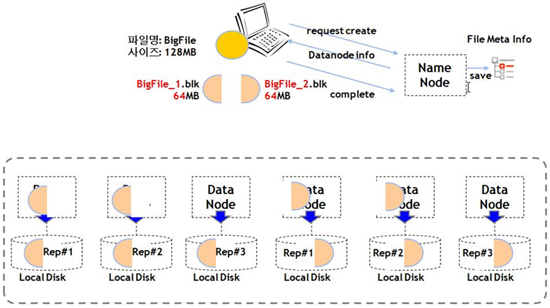
<그림5> DFS IO 작업
MapReduce 병렬처리
MapReduce는 분할-정복 방식으로 대용량 데이터를 병렬로 처리할 수 있는 프로그래밍 모델이다. 구글에서 MapReduce 방식의 분산컴퓨팅 플랫폼을 구현했고 성공적으로 적용해서 더욱 유명해졌으며 앞서 언급한 것처럼 Hadoop MapReduce 프레임워크가 동일한 기능을 가진다.
MapReduce 작업은 특별한 옵션을 주지 않으면 Map Task 하나가 1개의 블록(64MB)을 대상으로 연산을 수행한다. 예를 들어 320MB의 파일을 대상으로 작업을 수행하면 <그림 6>과 같이 5개의 Map Task가 생성되며 Map 과정에서 생산된 중간 결과물들을 Reduce Task들(사용자가 개수 지정)이 받아와서 정렬 및 필터링 작업을 거쳐 최종 결과물을 만들어 낸다.
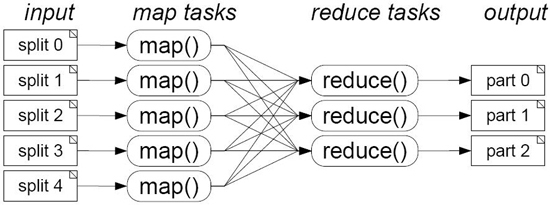
<그림6> MapReduce 구성도
구체적인 예를 들어 MapReduce가 어떻게 동작하는지 살펴보도록 하자. 단어별 개수를 계산하는 MapReduce 작업을 수행하려고 한다. 입력 데이터는 “This is a book…”와 “I Like..” 두 라인이고 각 라인별로 Map Task가 할당되어 총 2개의 Map Task가 생성되었다. 각각의 Map Task에서는 공백을 구분자로 해 Key-Value 쌍으로 단어-개수를 계산해 로컬 파일시스템에 중간 결과를 저장한다. Map 작업이 끝나면 Reduce Task에서는 Map Task의 중간 결과물을 가져와서 Key(단어)를 기준으로 정렬한 후 Value(단어 수)들의 값을 합산(Re duce)해 최종 산출물(단어-총 개수)을 만들어 낸다.
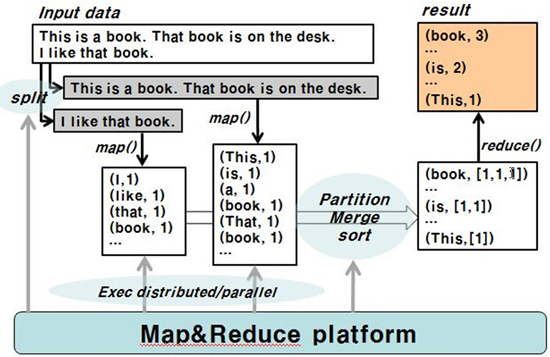
<그림7> 단어 수를 계산하는 MapReduce 작업
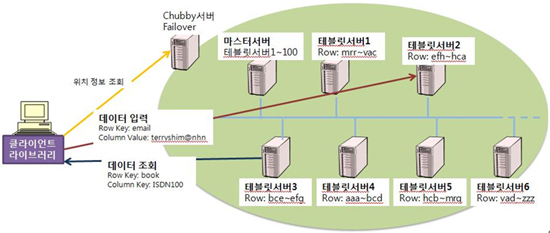
<그림8> 분산 데이터관리시스템 구성도
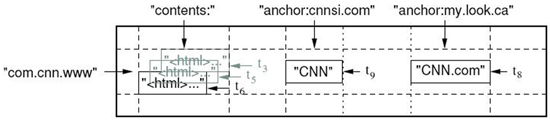
<그림9> 데이터 모델
분산 데이터관리시스템
앞에서 설명한 분산 파일시스템과 Map Reduce 프레임워크가 대용량 데이터를 처리하는 배치성 작업에 좀 더 적합한 기술이라면 분산 데이터관리시스템은 배치성 업무뿐만 아니라 실시간 응답성이 중요한 온라인 업무용으로도 사용할 수 있는 시스템이다. 구글에서는 BigTable이라는 이름의 분산 데이터관리시스템을 구현해 다양한 온/오프라인 업무에서 활용하고 있다. 이에 대응되는 공개 소프트웨어 프로젝트로서 아파치 HBase와 HyperTable 등이 있으며 기능 및 아키텍처 측면에서 Big Table과 거의 동일하다. 그렇다면 이러한 BigTable류의 분산 데이터관리시스템과 우리에게 익숙한 RDBMS는 어떤 차이점을 가지고 있고 또한 그 장점은 무엇일까? 분산 데이터관리시스템은 전통적인 RDBMS를 대체하기 위한 것은 아니다.
기존의 RDBMS가 트랜잭션 중심의 잘 구조화된 데이터를 조작하고 조회하기 위한 다양하고 진보된 기능들을 제공한다면 분산 데이터관리시스템은 이러한 기능보다는 높은 성능과 확장성 그리고 대용량 데이터 처리에 우선순위를 두었다. 즉 대용량 데이터를 네트워크상에 분산해 저장하고, 저장된 데이터를 이용해 분산/병렬 처리 작업을 수행하는 데 적합한 구조로 설계되고 구현된 시스템이다.
분산 데이터관리시스템은 마스터서버, 테블릿서버, 클라이언트 라이브러리 등 3개의 내부 컴포넌트로 구성되어 있으며 분산 파일시스템, MapReduce 같은 다양한 외부 시스템을 이용하고 있다.
먼저 데이터 모델을 살펴보자. BigTable류의 분산 데이터관리시스템은 Row, Column Family, Column, Timestamp 값을 갖는 다차원의 정렬된 Map으로 표현되며 다차원 Map 안의 값들은 바이트들의 연속된 배열이다. 일반적으로 많은 DBMS가 관계형 데이터 모델을 제공하고 있고 데이터 조회를 위해 Join 등의 연산을 제공해 준다. 반면에 분산 데이터관리시스템은 대용량 데이터 처리 시 적절한 응답속도를 보장하기 위해 Join 연산은 제공하지 않고 대신 모든 Row와 Column에 Index를 걸어서 데이터의 양이 커지더라도 일정 수준의 빠른 조회 및 접근을 가능하게 한다.
<그림 9>는 웹 페이지를 저장하는 테이블 한 부분을 표현한 것이다. Row 이름은 URL 명을 역(com. cnn.www)으로 표현한 것이다. “contents” Column Family는 웹 페이지의 내용을 가지며 “anchor” Column Family는 해당 웹 페이지를 참조하는 링크 명을 값으로 가진다. 즉 CNN의 홈페이지는 스포츠 일간지인 cnnsi.com과 my.look.ca의 홈페이지 내에서 참조가 되고 있음을 나타낸다.
테이블 데이터의 읽기와 쓰기 작업은 테블릿서버에서 수행된다. 하나의 쓰기 작업이 테블릿서버에 들어오면 서버는 해당 작업이 권한을 가지는지 점검한 후 Commit 로그에 먼저 기록하고, 콘텐츠는 Memtable이라는 메모리 테이블에 기록된다. 그리고 메모리 테이블은 일정 사이즈(보통 수십 MB)가 되면 SSTable이라는 물리적인 정렬된 Map 구조의 파일로 저장한다. 읽기 작업의 경우는 쓰기 작업과 마찬가지로 적절한 권한이 있는지를 점검한 후 Memtable과 SSTable을 통합한 논리적인 View 위에서 수행된다.

<그림10> 데이터 입력 및 조회
클러스터 관리시스템
클러스터 관리시스템은 클라우드 컴퓨팅의 각 플랫폼들이 유기적으로 상호작용할 수 있도록 조율해 주고 관리해 주는 시스템이다. 클러스터 관리 기술 중에서 클라우드 컴퓨팅의 주요 요소 기술인 서비스 프로비저닝을 살펴보자.

<그림11> 서비스 프로비저닝
서비스 프로비저닝은 운영체제, 소프트웨어, 환경정보, 스크립트 등을 관리하며 필요 시 설치 및 실행을 동적으로 수행할 수 있는 기술로, 이를 이용해 서비스들의 관리 및 배치 프로세스를 자동화할 수 있다. 예로 사용자의 요청을 제일 앞 단에서 받아 처리하는 웹 서버 5대가 있다고 가정하자. 사용자의 요청이 순간 급증해 웹 서버들의 부하가 가중되고 있으며 요청 처리도 늦어지고 있다. 웹 서버들의 과부하 상황을 즉시 감지한 클러스터 관리 시스템은 자원 상황(CPU, 메모리 등)이 좋은 5대의 유휴 서버를 선택해 프로비저닝 명령을 내린다. 명령을 받은 유휴 서버들은 분산 파일시스템에 접속해 웹 서버와 프로그램 등의 바이너리 및 환경 정보를 다운로드한다. 이후 다음 관리시스템이 지정한 스크립트나 절차를 차례대로 수행하면서 웹 서버 데몬을 실행시키고 사용자의 요청을 처리하게 된다. 이러한 방식으로 클러스터 관리 시스템은 실시간으로 사용자의 요청 처리를 위한 최적의 환경을 동적으로 구성할 수 있다.

